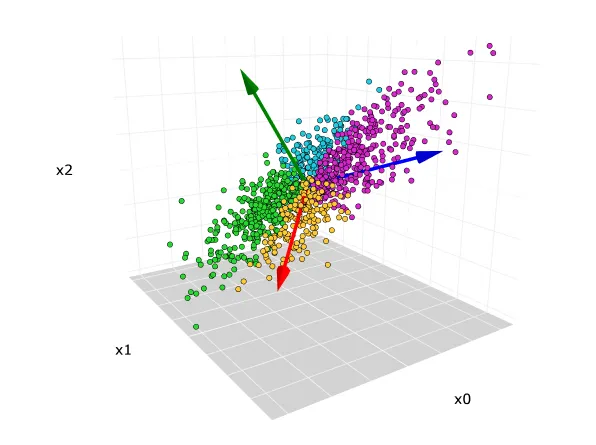
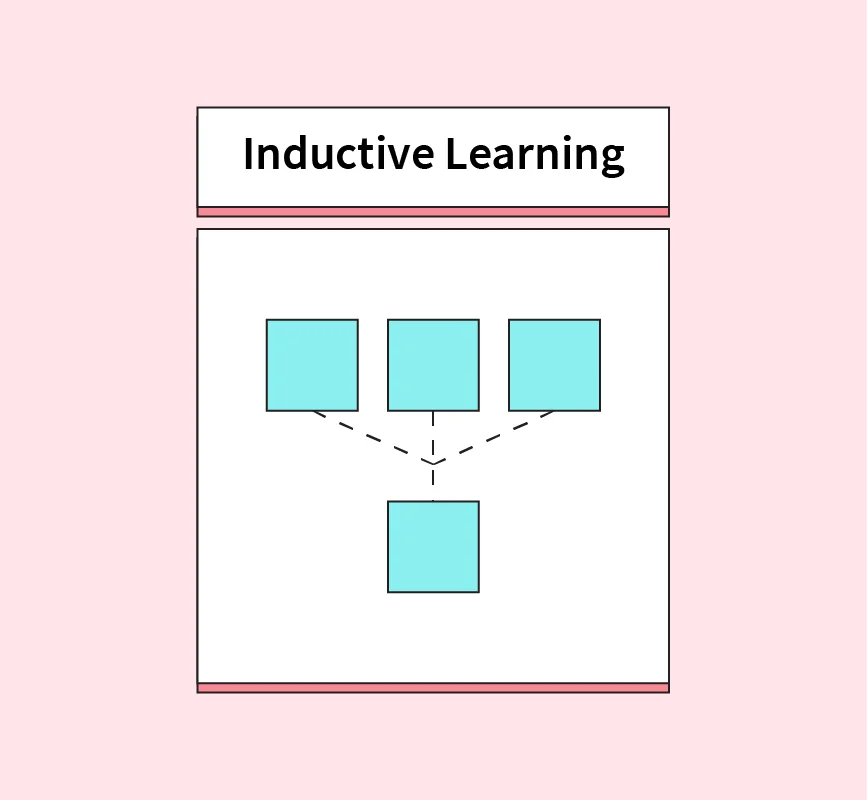
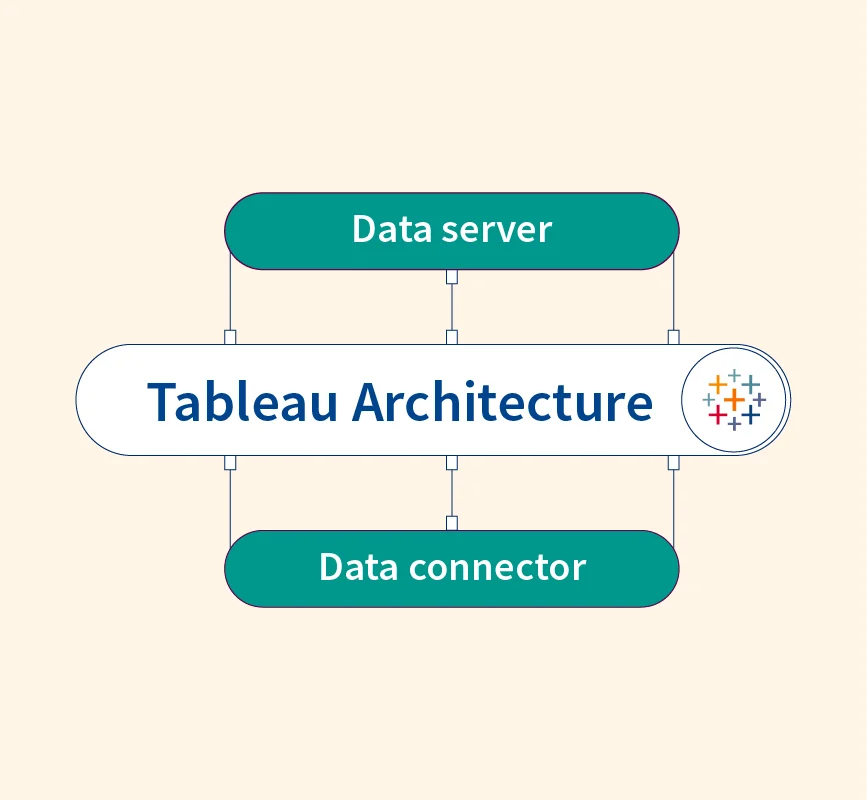
Data Science vs Artificial Intelligence
In today’s rapidly evolving tech landscape, both Data Science and Artificial Intelligence (AI) are driving major transformations across industries. These two fields have become essential for enabling companies to make data-driven decisions, automate processes, and create intelligent systems. However, despite their growing importance, many people still struggle to differentiate between the two. Understanding the distinctions ...