The AdaBoost algorithm, short for Adaptive Boosting, is a popular method in machine learning that belongs to the family of ensemble learning techniques. Ensemble learning combines multiple models, often referred to as “weak learners,” to create a strong, accurate model. Adaboost specifically focuses on improving the performance of weak learners (models that perform slightly better than random guessing) by combining them into a more robust system.
Introduced by Yoav Freund and Robert Schapire, Adaboost iteratively trains models, adjusting their focus on the data points that were previously misclassified. This process allows the algorithm to “adapt” and correct itself, making it particularly effective in scenarios like classification tasks where precision is crucial. By reweighting misclassified data points and emphasizing their importance in the next iteration, Adaboost enhances the overall performance of the combined model.
What is AdaBoost Algorithm in Machine Learning
AdaBoost (Adaptive Boosting) is an ensemble learning method that combines multiple weak learners to create a stronger model. A weak learner, like a simple decision stump, is a model that performs slightly better than random guessing. AdaBoost trains these weak learners in sequence, focusing on data points that were misclassified in previous rounds. By giving more weight to these challenging points, the algorithm adapts and improves, making it effective for classification tasks.
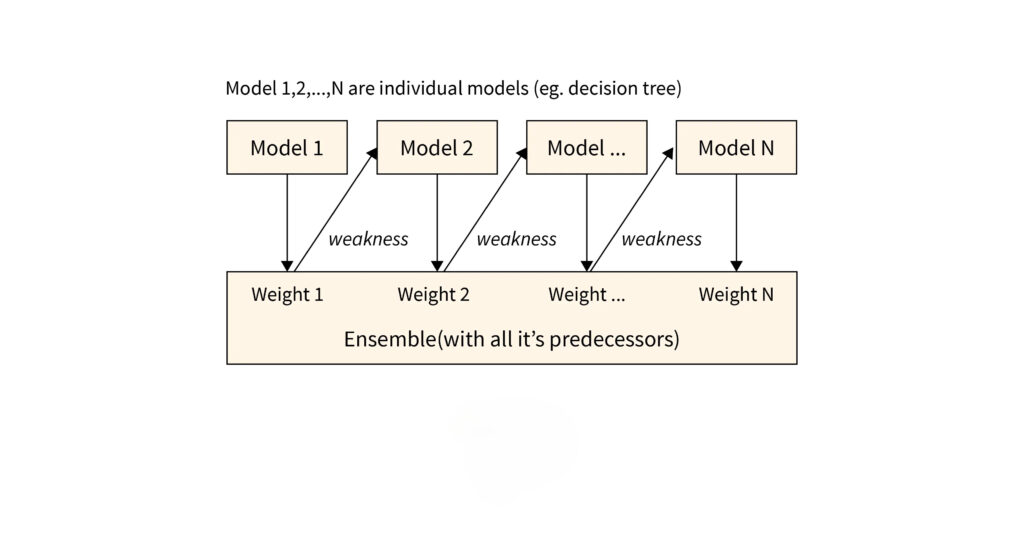
How Does AdaBoost Work?
The AdaBoost algorithm works by training weak learners in a sequence and focusing on correcting mistakes made in earlier steps. Here’s a simple breakdown of the process:
- Initialize Weights: All data points in the dataset are assigned equal weights at the start.
- Train the Weak Learner: The first weak learner is trained on the dataset using these initial weights.
- Calculate Error: The error rate is calculated based on the instances the weak learner misclassifies.
- Adjust Weights: The algorithm increases the weights of the misclassified instances, making them more significant in the next round of training.
- Repeat: A new weak learner is trained, now focusing more on the previously misclassified points. This process continues until a set number of learners are combined.
- Final Model: The weak learners are combined, with each one contributing based on its accuracy, to create a strong, overall model.
This iterative approach ensures that each weak learner improves the overall model by focusing on areas where previous learners struggled.
Key Concepts in AdaBoost
To understand how AdaBoost functions, it’s important to know the following key concepts:
- Weights on Data Points: AdaBoost assigns weights to every data point in the dataset. Initially, all points have equal weight. When a weak learner misclassifies a data point, its weight is increased, making the algorithm focus more on these challenging cases in subsequent rounds.
- Weak Learners: These are simple models, like decision stumps, that perform slightly better than random guessing. AdaBoost uses them iteratively, training each one to correct the mistakes of the previous learners.
- Strong Classifier: The final model, called the strong classifier, is a combination of all the weak learners. Each weak learner contributes based on its accuracy, and the algorithm combines their outputs using weighted voting to make a robust prediction.
- Error Rate: In each iteration, AdaBoost calculates the error rate of the current weak learner. The error rate determines how much influence the learner will have in the final model. A lower error rate means the learner contributes more to the strong classifier.
- Iterations: AdaBoost runs for multiple iterations, training weak learners sequentially. With each iteration, it updates the weights based on the performance of the previous learner. The number of iterations influences the strength of the final classifier but also impacts computation time.
Understanding and Implementation of AdaBoost Algorithm
To make the AdaBoost algorithm easy to follow, here’s a step-by-step breakdown:
1. Creating the First Base Learner:
- The algorithm starts by training the first weak learner (e.g., a decision stump) on the entire dataset, where all data points have equal weights.
2. Calculating the Total Error (TE):
- After training, the algorithm calculates the error rate (TE) based on the weights of misclassified data points. TE shows how well the weak learner performed.
3. Measuring the Performance of the Stump:
- The performance of the weak learner (e.g., the decision stump) is assessed using the error rate. The better the stump performs, the higher its influence in the final model.
4. Updating Weights:
- AdaBoost increases the weights of the misclassified instances and reduces the weights for correctly classified ones. This step ensures that the algorithm focuses on the challenging cases in the next round.
5. Creating a New Dataset:
- Based on the updated weights, a new dataset is generated for the next iteration. The algorithm selects data points with higher weights more frequently to prioritize misclassified cases.
6. Repeating the Process:
- These steps are repeated for multiple iterations, training additional weak learners and updating weights until the desired number of iterations is completed.
This process allows AdaBoost to progressively build a strong classifier by focusing on difficult data points, enhancing the model’s performance over time.
Python Implementation of AdaBoost
1. Problem Statement
We aim to build a classifier using AdaBoost to distinguish between two classes. We’ll use a sample dataset with features and a target variable for binary classification.
2. Import Libraries
First, we need to import the necessary libraries:
3. Reading and Describing the Dataset
We use a sample dataset for simplicity. You can load your dataset using pandas:
This code reads the dataset and displays the first few rows to understand its structure.
4. Dropping Irrelevant Columns and Separating Target Variable
Identify irrelevant columns and remove them. Separate the target variable from the feature set:
5. Unique Values in the Target Variable
Checking the number of unique values to confirm it’s a binary classification:
6. Splitting the Dataset
Split the dataset into training and testing sets to evaluate the model’s performance:
7. Applying AdaBoost
We apply the AdaBoost algorithm using the DecisionTreeClassifier as the base estimator:
Here, we set up DecisionTreeClassifier as our base learner with a depth of 1 (decision stump). The n_estimators parameter indicates the number of iterations (weak learners) AdaBoost will create.
8. Accuracy of the AdaBoost Model
Finally, we check the accuracy of the AdaBoost model on the test data:
This code snippet provides a basic AdaBoost implementation using scikit-learn in Python. The model’s performance can be evaluated using accuracy, as demonstrated above.
Advantages and Disadvantages of AdaBoost
Advantages of AdaBoost:
- Improved Accuracy: AdaBoost often provides better accuracy than individual models by combining multiple weak learners into a stronger classifier.
- Adaptability: The algorithm adapts to errors by focusing on misclassified points, which enhances its ability to handle complex classification tasks.
- Ease of Implementation: AdaBoost is easy to implement using standard libraries like scikit-learn and can be combined with various weak learners, such as decision trees.
- Versatility: It works well with both binary and multi-class classification problems and can also be extended to handle regression tasks.
- Handles Imbalanced Datasets: By emphasizing challenging cases, AdaBoost can effectively handle imbalanced datasets where one class is underrepresented.
Disadvantages of AdaBoost:
- Sensitive to Noisy Data: AdaBoost can be overly influenced by outliers or noisy data points, which may lead to poor performance if the data contains many such points.
- Computationally Intensive: Training multiple learners sequentially can be time-consuming, especially for large datasets or when using complex models.
- Overfitting: If not properly tuned, AdaBoost may overfit, particularly if too many weak learners are used or if the model complexity is too high.
- Limited Flexibility with Weak Learners: AdaBoost relies heavily on the performance of weak learners. If these models are too simple or ineffective, the final classifier may not perform well.
Practical Applications of AdaBoost
AdaBoost is widely used in various fields due to its adaptability and effectiveness. Here are some common practical applications:
- Face Detection: AdaBoost is a fundamental component in face detection algorithms, such as the Viola-Jones face detector. It quickly identifies facial features by combining simple weak learners into a strong classifier, making it efficient for real-time applications.
- Spam Filtering: Email spam filters use AdaBoost to classify messages as spam or not spam. By training the algorithm on features such as keywords and email metadata, AdaBoost builds a model capable of accurately identifying spam emails.
- Anomaly Detection: In cybersecurity, AdaBoost is used to detect anomalies or malicious activities. The algorithm can learn patterns in network behavior and identify deviations, which may indicate potential threats.
- Sentiment Analysis: AdaBoost can be applied to natural language processing (NLP) tasks like sentiment analysis, where it classifies text as positive, negative, or neutral based on features extracted from the text.
- Medical Diagnosis: AdaBoost is also used in the healthcare industry for medical diagnosis, where it helps classify diseases or medical conditions based on patient data, such as symptoms or test results.
The Way of Deciding the Output of the Algorithm for Test Data
AdaBoost combines the predictions of all the weak learners through a weighted voting system to decide the final output for test data. Here’s how it works:
- Weighted Voting: Each weak learner’s prediction is weighted based on its accuracy during training. Learners with lower error rates have higher weights, meaning they have more influence on the final decision.
- Aggregating Predictions: For a given test data point, each weak learner makes a prediction. AdaBoost aggregates these predictions by summing the weighted votes. If the majority of weighted votes lean towards one class, that class is chosen as the output.
- Final Decision: The final output for the test data is the class with the highest sum of weighted votes. This method ensures that the most accurate weak learners contribute more to the final prediction, improving the model’s overall accuracy.
This weighted voting approach allows AdaBoost to combine multiple weak learners into a single strong classifier, making it effective in classification tasks.
Conclusion
AdaBoost, or Adaptive Boosting, enhances weak learners by focusing on misclassified points and combining them through weighted voting to create a strong classifier. Its adaptability makes it useful for tasks like face detection and spam filtering. While it offers improved accuracy, it can be sensitive to noisy data and may overfit. Understanding these factors helps determine when AdaBoost is most effective.


