Neural networks have become the backbone of modern machine learning and artificial intelligence applications. From image recognition to natural language processing, neural networks are responsible for transforming large amounts of data into actionable insights. A critical element that determines the performance of neural networks is the activation function, which plays a key role in enabling the network to learn complex patterns. In this article, we’ll explore the role of activation functions, their types, and why they are indispensable in the functioning of neural networks.
What is an Activation Function?
An activation function is a mathematical equation that determines the output of a neuron within a neural network. Activation functions are used to introduce non-linearity into the model, allowing the neural network to solve complex problems that are not linearly separable. In essence, activation functions decide whether a neuron should be activated or not, based on the weighted sum of inputs passed through the neuron.
Without activation functions, neural networks would only be able to perform linear transformations, which severely limits their capacity to solve complex problems. Activation functions enable the network to learn intricate patterns by allowing non-linear transformations, facilitating decision-making at each layer of the network.
Elements of a Neural Network
A typical neural network consists of several layers, each responsible for specific functions:
Input Layer
The input layer is where data enters the network. Each neuron in this layer represents a feature of the dataset. The input layer passes the data through weighted connections to the hidden layers, where it is processed.
Hidden Layer
The hidden layers are where most of the data processing occurs. Neurons in these layers apply activation functions to transform the data, identifying patterns and relationships within the dataset. Depending on the network’s architecture, there may be multiple hidden layers in a deep neural network.
Output Layer
The output layer is responsible for producing the final result or prediction. The number of neurons in the output layer depends on the task; for instance, a binary classification problem will have one neuron, while a multi-class problem will have multiple neurons, each representing a class.
Neural networks are trained through processes such as feedforward and backpropagation, where weights are adjusted based on the error calculated between the actual and predicted outcomes.
Why Do We Need Non-linear Activation Functions?
Linear transformations have limited representational power, which is why non-linear activation functions are essential in neural networks. These functions allow the network to model complex patterns and relationships that are not possible with linear models.
Linear vs. Non-linear Transformations
In a linear activation function, the output is directly proportional to the input, which means the network can only learn a straight line to separate classes. This limits the model’s performance, especially in problems where data is not linearly separable.
Non-linear activation functions, on the other hand, enable the network to create curved decision boundaries, allowing it to handle complex, non-linear relationships in the data.
Importance of Non-linearity
By introducing non-linearity into the model, activation functions allow the network to learn from the data in a more nuanced way. Non-linear functions like ReLU and sigmoid transform inputs into non-linear outputs, giving the network the flexibility to solve a wider range of problems. For example, non-linear activation functions are crucial in applications like image recognition, where the relationship between input pixels and the final classification is highly complex.
Types of Activation Functions
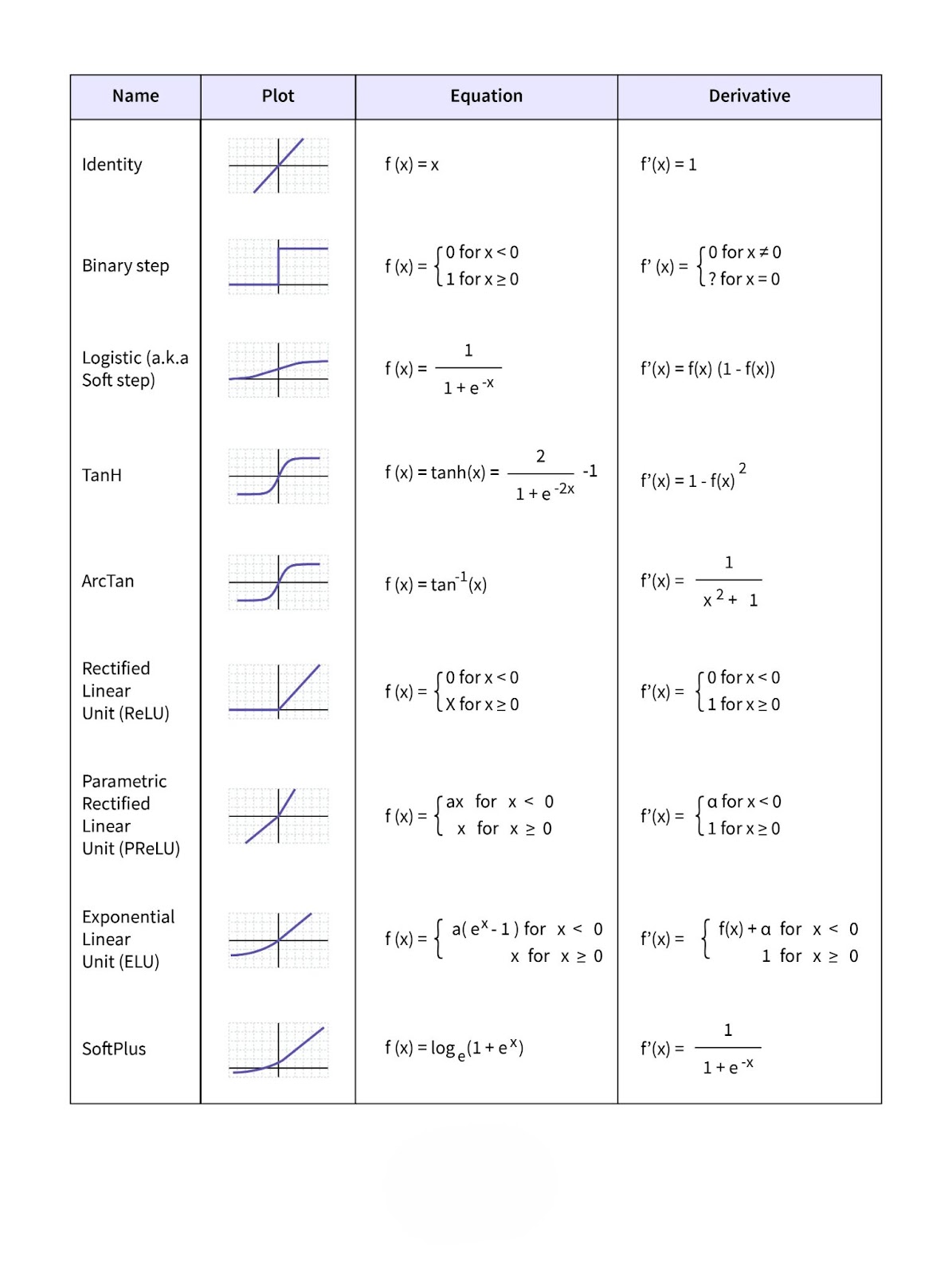
1. Linear Activation Function
The linear activation function produces an output that is directly proportional to the input. While simple, it is rarely used in deep learning due to its inability to introduce non-linearity into the model.
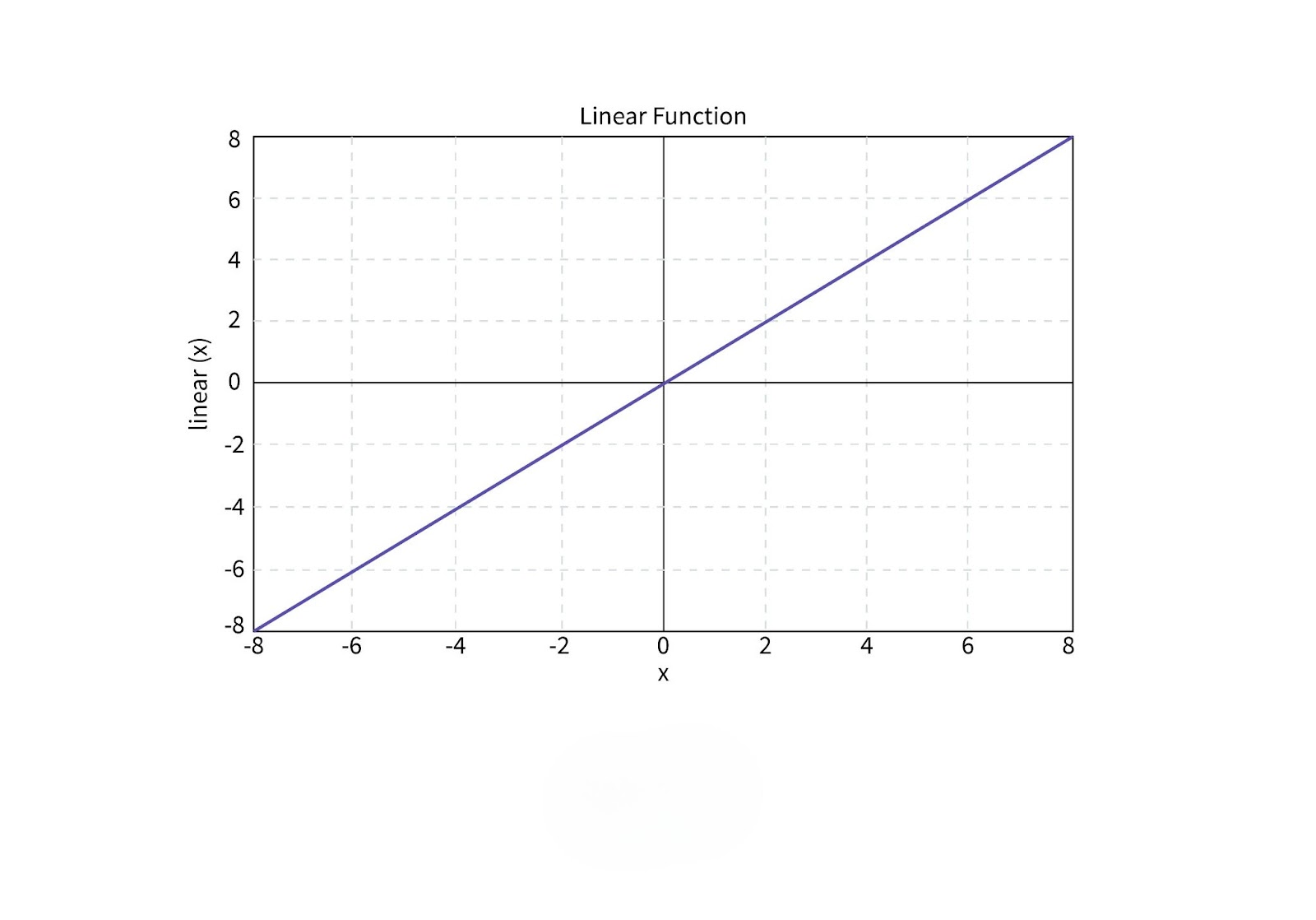
- Characteristics: Linear activation functions are computationally efficient but lack the ability to solve complex tasks.
- Limitations: The primary drawback is the lack of non-linearity, which prevents the network from learning intricate patterns.
2. Binary Step Function
The binary step function outputs either a 0 or 1 depending on whether the input is above or below a certain threshold. While useful in basic binary classification tasks, this function is not suitable for problems that require a gradient-based optimization, as it does not provide useful gradients for learning.
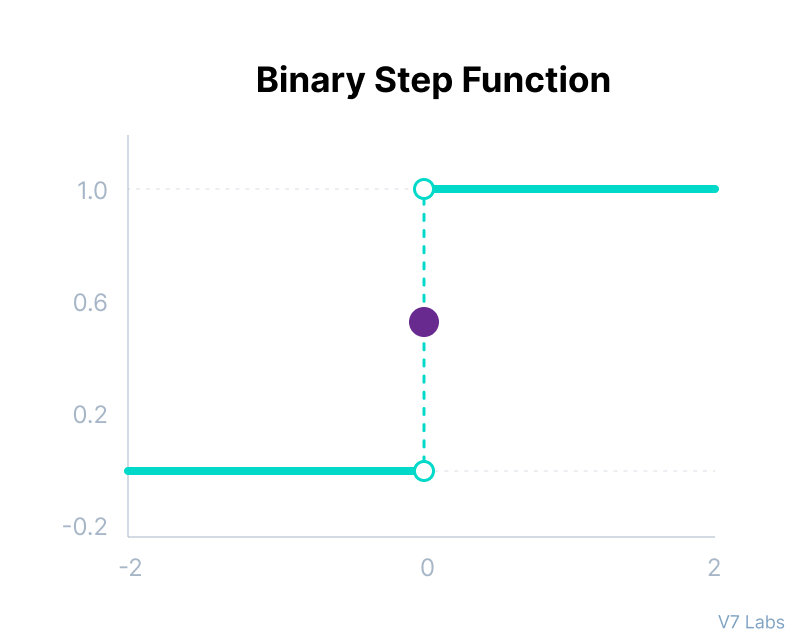
Source: V7 Labs
- Use Case: Binary step functions are mostly used in simple decision-making systems.
3. Sigmoid (Logistic) Function
The sigmoid function maps the input to a value between 0 and 1, making it useful for binary classification problems. Its smooth gradient makes it useful in backpropagation; however, it suffers from the vanishing gradient problem when used in deep networks.
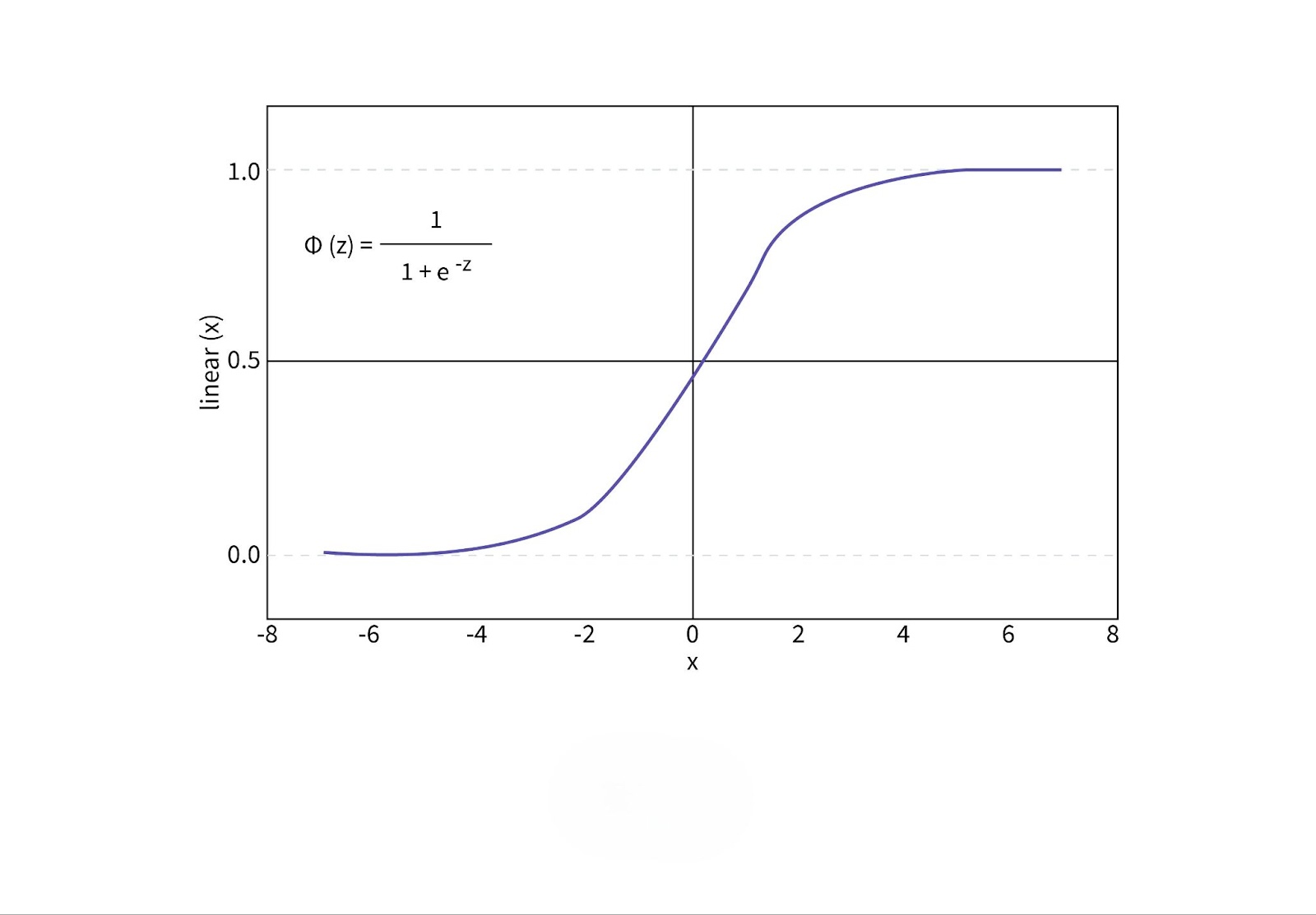
- Mathematical Formula: $$S(x) = \frac{1}{1 + e^{-x}}$$
- Advantages: The sigmoid function is intuitive and works well for problems where outputs need to be interpreted as probabilities.
- Limitations: It causes vanishing gradients in deep networks, making it difficult to optimize the model.
4. Tanh (Hyperbolic Tangent) Function
The tanh function is similar to the sigmoid function but maps the input to values between -1 and 1, making it zero-centered. This improves the learning process by ensuring that the mean activation remains close to zero.
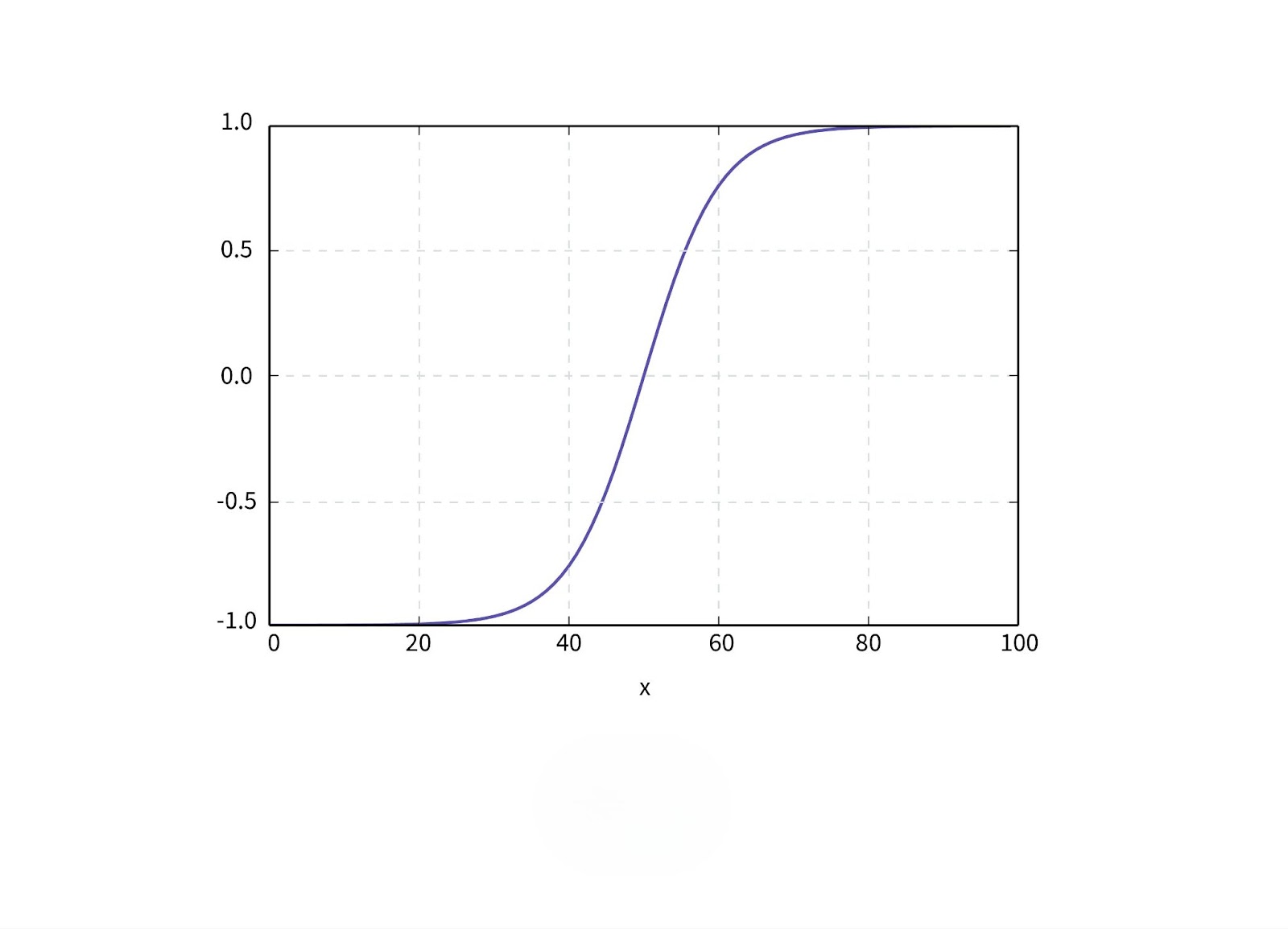
- Mathematical Formula: $$\text{tanh}(x) = \frac{e^x – e^{-x}}{e^x + e^{-x}}$$
- Advantages: The zero-centered output leads to a faster and more efficient learning process compared to sigmoid.
- Limitations: Like sigmoid, tanh also suffers from the vanishing gradient problem in deep networks.
5. ReLU (Rectified Linear Unit) Function
The ReLU function is one of the most widely used activation functions in deep learning. It outputs the input directly if it is positive and zero otherwise. ReLU is computationally efficient and addresses the vanishing gradient problem.
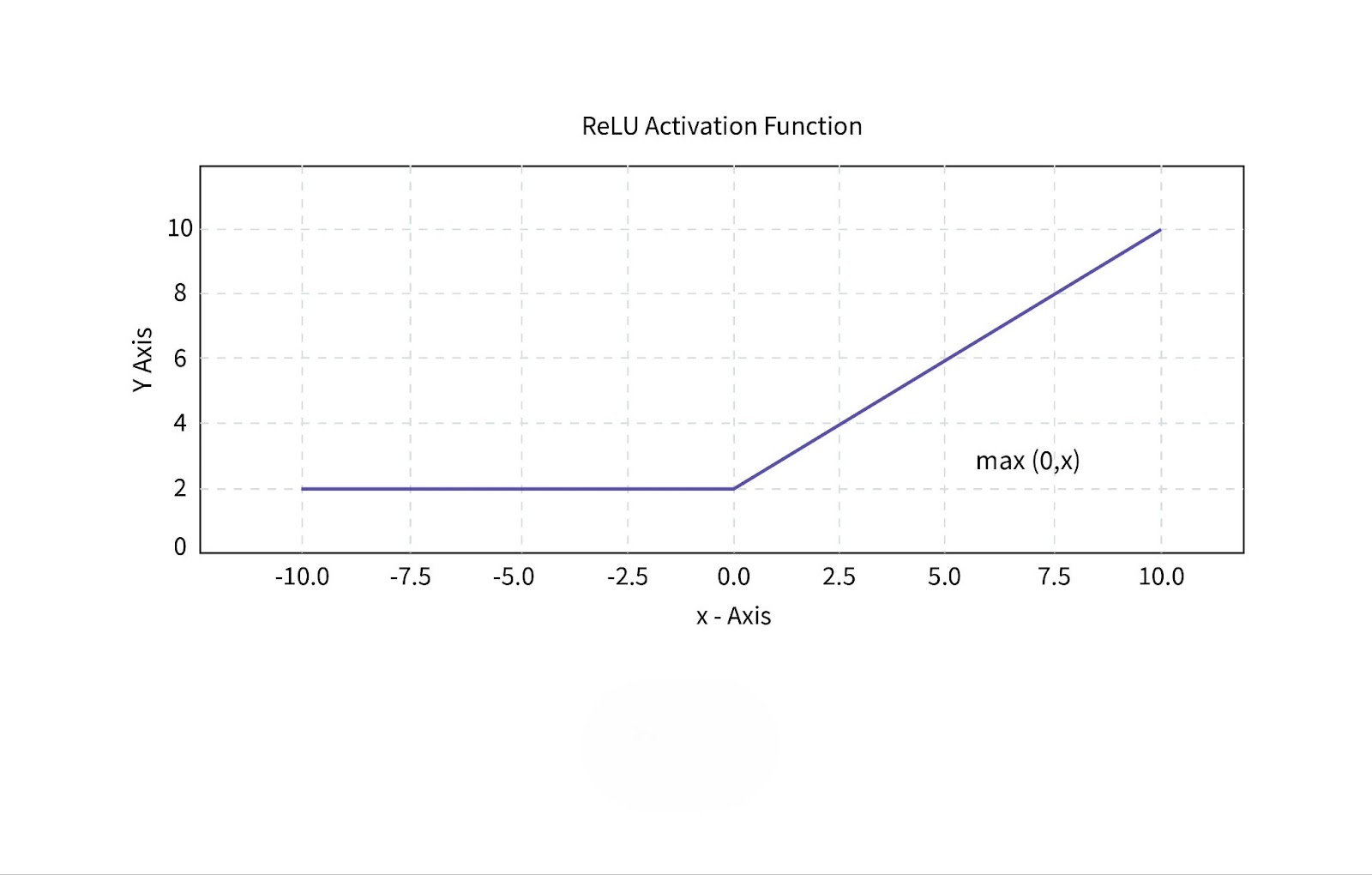
- Advantages: ReLU is fast to compute and helps avoid the vanishing gradient problem, making it ideal for deep neural networks.
- Limitations: ReLU can suffer from the dying ReLU problem, where neurons stop learning if their output becomes permanently zero.
6. Leaky ReLU
Leaky ReLU is a variation of the ReLU function that allows a small, non-zero output for negative input values. This prevents neurons from “dying” by giving them a small gradient when their input is negative.
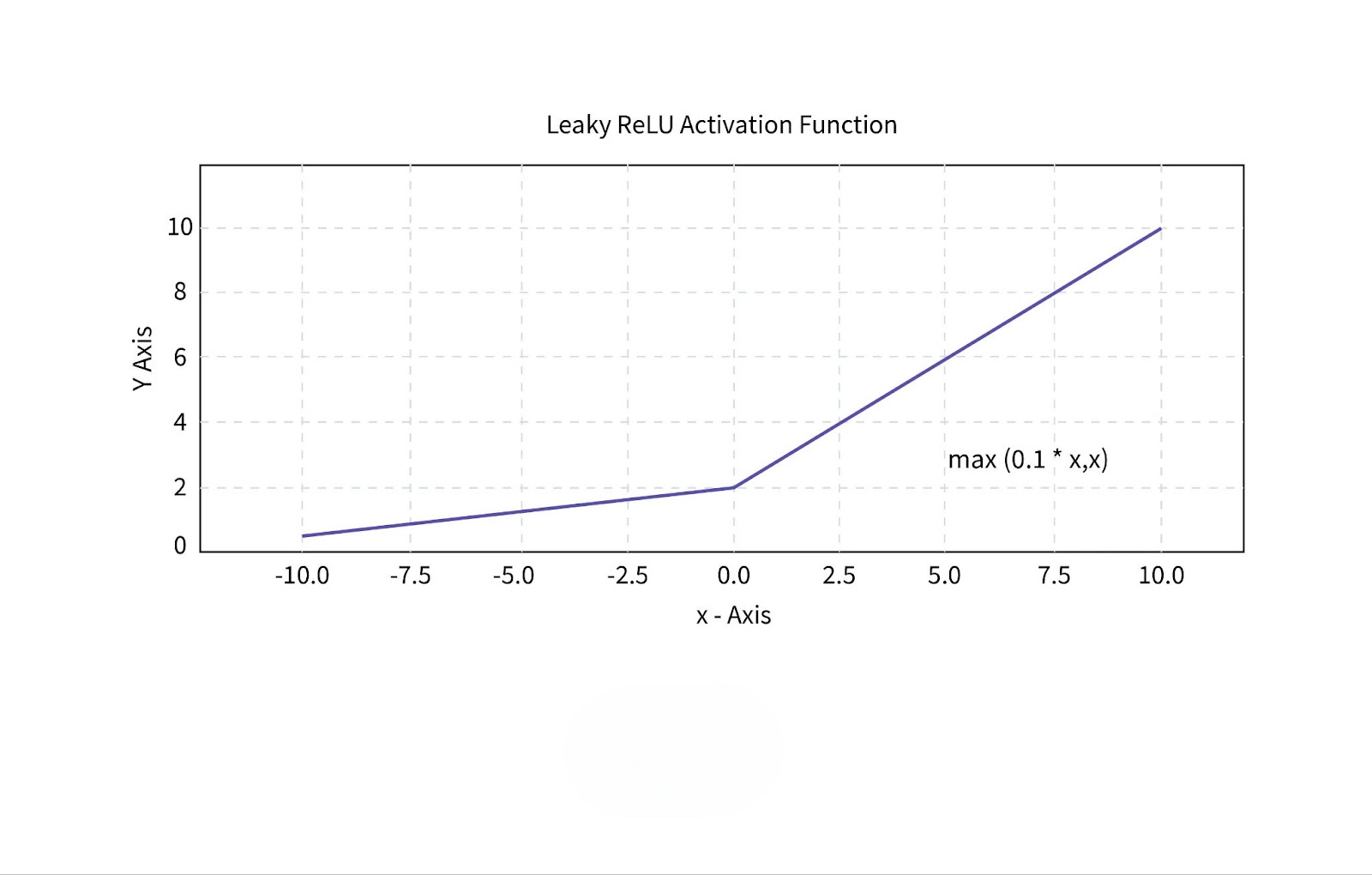
- Advantages: Leaky ReLU solves the dying ReLU problem, improving model performance in deep networks.
- Limitations: It requires careful tuning of the leak parameter to ensure optimal performance.
7. Parametric ReLU
Parametric ReLU (PReLU) is another variation of ReLU, where the slope of the negative part of the function is learned during training. This gives the model more flexibility compared to standard ReLU.
- Advantages: PReLU offers improved performance in deep networks by allowing the network to learn the best slope for negative inputs.
- Limitations: It introduces additional parameters that must be learned, which can increase computational complexity.
8. Softmax Function
The softmax function is used in multi-class classification problems to convert raw output scores into probabilities. Each output represents the probability of the input belonging to a particular class.
- Mathematical Formula: $$\text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}}$$
- Advantages: Softmax is essential for multi-class classification tasks where the outputs need to be interpreted as probabilities.
9. Swish
Swish is a newer activation function developed by Google, and it has shown to outperform ReLU in certain deep learning models. It is a smooth function that combines the benefits of both ReLU and sigmoid.
- Formula: $$\text{Swish}(x) = x \cdot \text{sigmoid}(x)$$
- Advantages: Swish produces smooth, non-zero gradients, which helps improve model convergence in deep networks.
10. Gaussian Error Linear Unit (GELU)
GELU is used in advanced deep learning models like transformers and natural language processing (NLP) applications. It is a probabilistic function that weights inputs by their values and applies a smooth non-linearity.
- Advantages: GELU has shown to improve model performance in tasks like language modeling and NLP.
- Limitations: It is computationally more expensive than ReLU or other standard activation functions.
Challenges in Training Deep Neural Networks
Vanishing Gradients
The vanishing gradient problem occurs when the gradients of the loss function become too small, slowing down the learning process. Activation functions like sigmoid and tanh are more prone to this problem in deep networks.
Exploding Gradients
The exploding gradient problem is the opposite of vanishing gradients, where gradients become too large, causing unstable learning. ReLU and its variations help mitigate this issue by ensuring that gradients are neither too large nor too small.
How to Choose the Right Activation Function?
When selecting an activation function, several factors must be considered:
- Problem Type: For binary classification, sigmoid is effective, while softmax is better suited for multi-class classification.
- Model Architecture: Deep networks often benefit from ReLU or its variants to avoid vanishing gradients.
- Training Dynamics: The learning rate and optimization algorithm can also influence which activation function is most suitable for the model.
Conclusion
Activation functions are essential for enabling neural networks to learn complex patterns and solve challenging problems. From simple binary step functions to more advanced options like Swish and GELU, each activation function offers unique benefits depending on the task at hand. As neural networks continue to evolve, choosing the right activation function will remain a key factor in optimizing model performance.
References:


